

In this post we introduce the recurrent neural network (RNN) model in natural language processing (NLP), as well as two improvements over it, long short-term memories (LSTM) and gated recurrent units (GRU).
Natural languages are non-linear. Flows of words and sentences in texts often do not follow simple and predictable patterns. The probability of a word appearing at position $i$ may depend on some words at very far past, instead of always depending on 2 or 3 words behind it. The RNN model is an attempt to address the challenge of long term dependencies.
Recurrent Neural Networks (RNN)
Suppose we are predicting $y_1,\ldots,y_n$ for input sequence $x_1,\ldots,x_n$. RNN’s solution is to re-use $h_{t-1}$, the output of the hidden layer at time $t-1$, in the calculation for $h_t$:
\[\begin{align} h_t &= g(Uh_{t-1} + Wx_t),\\ y_t &= f(Vh_t). \end{align}\]Since $h_{t-1}$ is a function of $x_{t-1}$, its values should incorporate information about $x_{t-1}$, and so by adding it into the calculation for $h_t$, information about $x_{t-1}$ should be passed to $h_t$ and then to the output $y_t$. See Figure 1 for the illustration of the RNN architecture. By passing information this way, it is hoped that useful information in $x_1,\ldots,x_{t-1}$ can all be used in the calculation for $y_t$.
 Figure 1: RNN Architecture
Figure 1: RNN Architecture
To train RNN as a language model (Figure 2), for each word $x_i$ in the input sequence we output a softmax probability distribution for the next word. We minimize the NLL loss (or CrossEntropy loss) of the model output on the training corpus, by gradient descent algorithms.
 Figure 2: Applications of RNN – language modeling
Figure 2: Applications of RNN – language modeling
Training RNN for sequence labeling (Figure 3) is similar for training a language model, where we output probabilities over labels for each input and maximize the probability for the correct label.
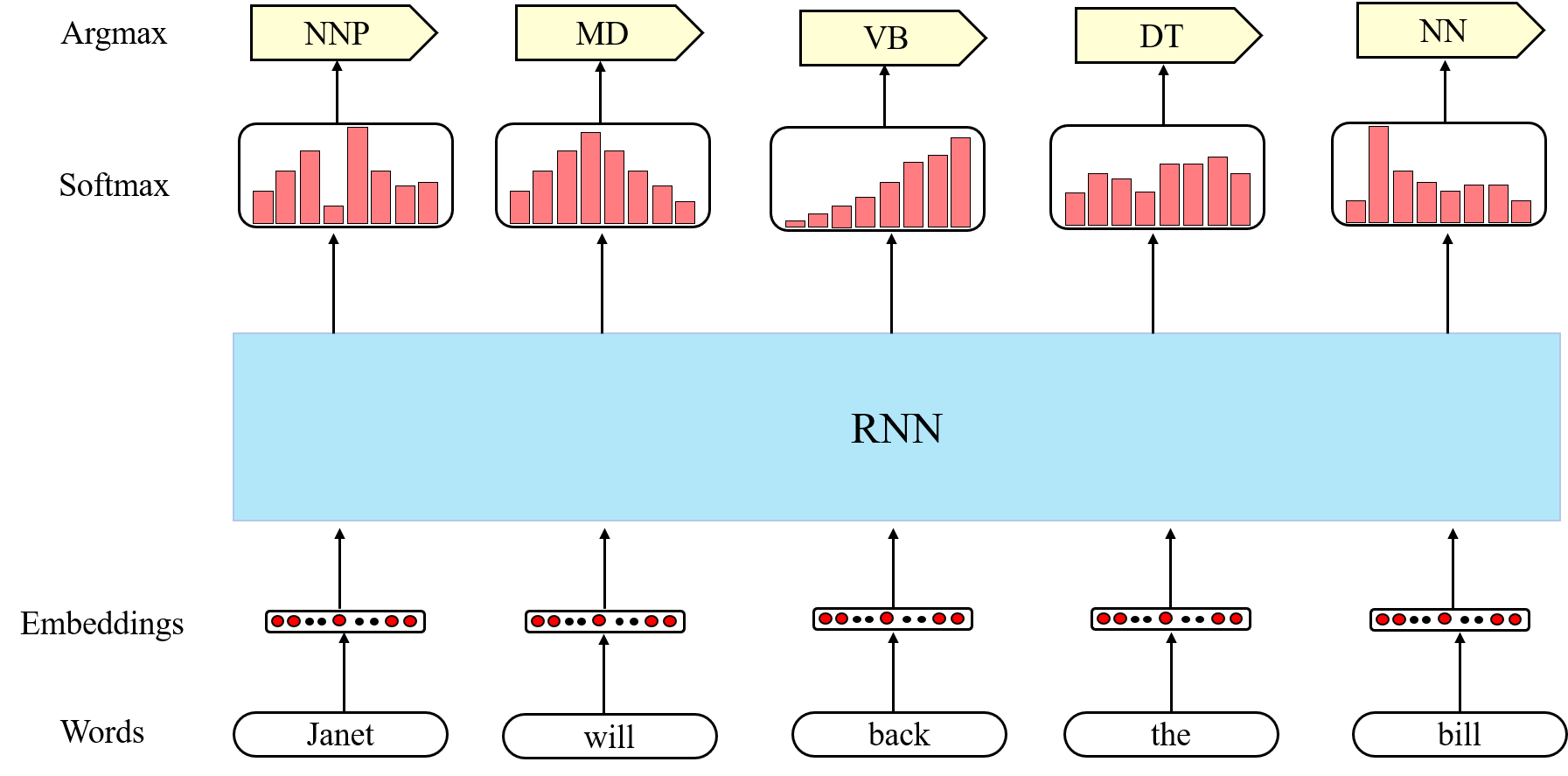 Figure 3: Applications of RNN – sequence labeling
Figure 3: Applications of RNN – sequence labeling
We can also apply RNN to sequence classification (Figure 4), where an entire document, paragraph or sentence is classified as belonging to some category of interest. The final hidden layer $h_n$ is taken to constitute a compressed representation of the entire sequence. In the simplest approach, $h_n$ serves as the input to a subsequent feedforward network that outputs softmax probabilities over all categories. The use of loss from a downstream application to adjust weights all the way through the network is referred to as end-to-end training.
 Figure 4: Applications of RNN – sequence classification
Figure 4: Applications of RNN – sequence classification
Besides simple recurrent networks (SRN), there are stacked RNNs where you can stack multiple RNNs together. There are also bidirectional RNNs (Figure 5 & 6) where two seperate RNNs are trained in forward and backward directions respectively, and outputs from the two models are combined to form final output, by concatenation, element-wise summation, multiplication or averaging.
 Figure 5: Bidirectional RNN for sequence labeling
Figure 5: Bidirectional RNN for sequence labeling
 Figure 6: Bidirectional RNN for sequence classification
Figure 6: Bidirectional RNN for sequence classification
Now let’s talk about drawbacks of recurrent neural networks. First, after going through multiple composite functions, information about the first few inputs $x_1,x_2,\ldots$ can still be easily lost. Second, each element in input sequence is processed sequentially, which leads to a slow running time.
Long Short-Term Memories (LSTM)
To address the vanishing information problem in RNN, LSTM:
- adds an explicit context layer to the architecture;
- uses gates to control the flow of information.
 Figure 7: Architecture for the LSTM unit
Figure 7: Architecture for the LSTM unit
See Figure 7 for the architecture. It accepts $c_{t-1},h_{t-1}$ and $x_t$ as inputs, and produces $c_t$ and $h_t$ as outputs. Each gate is a layer with its own parameters ${U, W}$, and $\sigma$ as the activation function. Parameters of the gates are adjusted automatically during training for automatic context management (deleting or adding information). This avoids hand-crafted rules. The hope is that, by multiplying with the outputs from the forget gate, which should all be close to $0$ or $1$, useful information in previous context is retained, and information that is no longer needed is removed. Similar reasoning for the add gate and the output gate.
We can summarize LSTM into two equations:
\[\begin{cases} c_t = c_{t-1} \odot f + g \odot a\\ h_t = \tanh(c_t) \odot o \end{cases}\]where $f, g, a$ and $o$ are all neural network mappings of inputs $h_{t-1}$ and $x_t$, each with their own parameters.
Gated Recurrent Units (GRU)
LSTM introduces a considerable amount of additional parameters. To ease this burden, gated recurrent units (GRUs) dispense the use of a separate context vector, and use only two gates, a reset gate $r$ and an update gate $z$:
\[\begin{align} r_t &= \sigma(U_rh_{t-1} + W_rx_t)\\ z_t &= \sigma(U_zh_{t-1} + W_zx_t)\\ \end{align}\]The reset gate $r_t$ is a binary-like mask that either blocks information with values near zero or allows information to pass through unchanged with values near one. The update gate $z_t$ mixes the old hidden state and the new one.
\[\begin{align} \tilde{h}_t &= \tanh\left\{U(r_t\odot h_{t-1}) + Wx_t\right\}\\ h_t &= (1-z_t)h_{t-1} + z_t\tilde{h}_t. \end{align}\]See Figure 8 for the 4 basic neural units commonly used in RNNs for language modeling. This kind of modularity is key to the applicability of LSTM and GRU units.
 Figure 8: Comparison of 4 neural units
Figure 8: Comparison of 4 neural units
Summary
Recurrent neural networks are designed to specifically model sequential data like texts. LSTM and GRU architectures are designed to further retain information. RNNs were once widely used in NLP, but now the focus has been shifted to Transformer based models like BERT, which we will introduce in the next post.
Cite as:
1
2
3
4
5
6
7
@article{lifei2022rnn,
title = "RNN, LSTM and GRU",
author = "Li, Fei",
journal = "https://lifeitech.github.io",
year = "2022",
url = "https://lifeitech.github.io/posts/rnn/"
}
Comments powered by Disqus.